MCO: inferencia y levantamiento de supuestos
Econometría I
Paula Pereda (ppereda@correo.um.edu.uy)
17 de setiembre de 2021
Bondad de ajuste
Bondad de ajuste
Estadístico t - ¡de nuevo!
El modelo poblacional lo escribimos de la siguiente manera:
y=β0+β1x1+…+βkxk+μ
Distribución t para estimadores estandarizados:
Bajo los supuestos del modelo lineal clásico (MLC),
(^βj−βj)/ee(^βj)∼tn−k−1 donde k+1 es la cantidad de parámetros desconocidos en el modelo poblacional y=β0+β1x1+…+βkxk+μ, o sea k parámetros de pendiente y el intercepto β0.
- Testeo: H0 )βj=0
- Ejemplo: salarioi=β0+β1educacióni+β2experienciai+β3antigüedadi+μi
- ¿Qué significa testear: H0 )βj=0 en este caso?
Bondad de ajuste
Estadístico de prueba t
t^βj=^βjee(^βj)
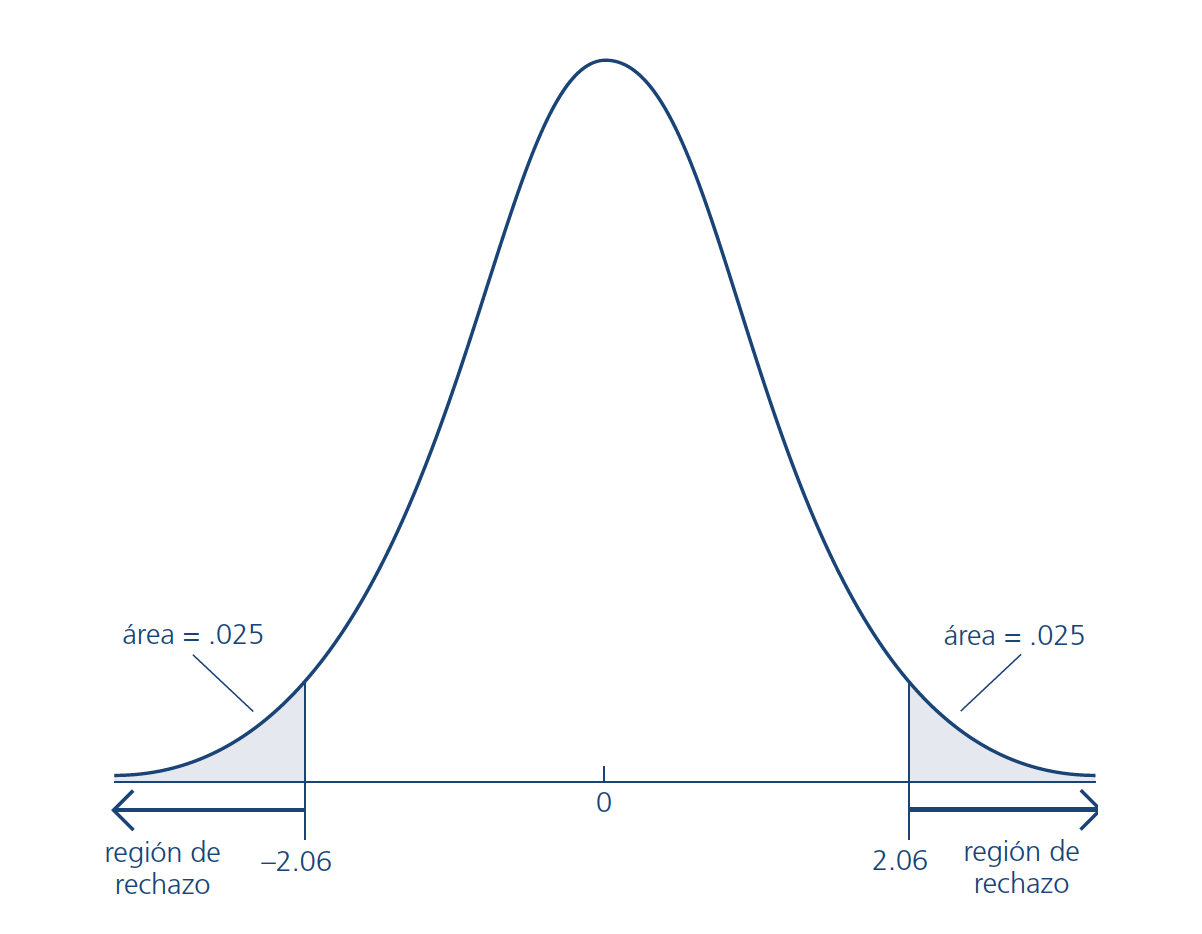
- A dos colas la regla de rechazo es ∣∣t^βj∣∣>c
- Para encontrar c, definir α, en general 5%
- Suponiendo que N−k−1=25
Bondad de ajuste
Valor-p para el estadístico t
Alternativamente, podemos calcular el valor p que acompaña a nuestro estadístico de prueba, que efectivamente nos da la probabilidad de ver nuestro estadístico de prueba o nuestro estadístico de prueba más extrema si la hipótesis nula fuera cierta.
Valores p muy pequeños, generalmente <0.05, significan que sería poco probable que veamos nuestros resultados si la hipótesis nula fuera realmente cierta; tendemos a rechazar el valor nulo para valores p por debajo de 0.05.
Bondad de ajuste
Valor-p para el estadístico t
Quitar arbitriariedad del nivel de significación elegido
El valor p es la probabilidad de obtener valores de la prueba estadística que sean mayores o iguales (o más extremos) que el efectivamente observado si H0 ) es cierto
No rechazar H0 ) si p>α. En otro caso rechazar. Cuanto más chico es el p más fuerte es el rechazo.
Recordar que, en principio, queremos rechazar H0 ) pues esto implica decir que hay evidencia para decir que βj es significativamente diferente de cero.
Bondad de ajuste
Estadístico F
El estadístico F se utiliza para contrastar hipótesis conjuntas sobre los coeficientes de regresión.
Las fórmulas para el estadístico F están integradas en los paquetes informáticos.
Caso de dos restricciones:
Cuando la hipótesis nula conjunta tiene las dos restricciones de que β1=0 y β2=0, el estadístico F combina los dos estadísticos t, t1 y t2, mediante la fórmula:
F=12⎛⎜⎝t21+t22−2^ρt1,t2t1t2)1−^ρ2t1,t2⎞⎟⎠ donde ^ρt1,t2 es un estimador de la correlación entre los dos estadísticos t.
Bondad de ajuste
Estadístico F
- Caso general de q restricciones:
Bajo la hipótesis nula, el estadístico F tiene una distribución muestral que, en muestras grandes, está dada por la distribución Fq,∞. Es decir, en muestras grandes, bajo la hipótesis nula el estadístico F se distribuye Fq,∞.
Aplicaciones en R
Levantamiento de supuestos
Recordemos los supuestos...
Supuesto 1. Linealidad en parámetros. y=β0+β1x1+⋯+βkxk+u
Supuesto 2. Muestra aleatoria. {(yi,xi):i=1,…,n} son variables aleatorias i.i.d.
Supuesto 3. Exogeneidad estricta. E(u∣x1,…,xk)=0
Supuesto 4. No multicolinealidad. En la muestra, ninguna de las variables independientes es constante y no hay relaciones lineales exactas entre las variables independientes.
Recordemos los supuestos...
Supuesto 5. Homocedasticidad y ausencia de autocorrelación. Var(u∣x1,…,xk)=σ2 (homocedasticidad) y COV(ui,uj∣x1,…,xk)=0
Supuesto 6. Normalidad. u∣∣x∼N(0,σ2)∣∣
Omisión de variable relevante

Omisión de variable relevante
Sesgo de variable omitida Si el regresor está correlacionado con una variable que ha sido omitida en el análisis y ésta determina, en parte, la variable dependiente, el estimador MCO presentará sesgo de variable omitida.
El sesgo de variable omitida se produce cuando se cumplen dos condiciones:
(1) cuando la variable omitida está correlacionada con los regresores incluidos en la regresión y
(2) cuando la variable omitida es un factor determinante de la variable dependiente.
Ejemplos:
Ejemplo #1: Porcentaje de estudiantes de inglés.
Ejemplo #2: La hora del día de la prueba.
Ejemplo #3: Espacio de aparcamiento por alumno.
Omisión de variable relevante
El sesgo de variable omitida significa que el tercer supuesto de mínimos cuadrados, que E(u∣x1,…,xk)=0, no se cumple.
¿Por qué se incumple el supuesto 3?
Recordemos el término de error ui en el modelo de regresión lineal con un único regresor representa todos los factores, distintos de Xi, que son determinantes de Yi.
- Si uno de esos otros factores está correlacionado con Xi, esto significa que el término de error (que contiene a este factor) está correlacionado con Xi. En otras palabras, si una variable omitida es un determinante de Yi, entonces está en el término de error, y si está correlacionada con Xi, entonces el término de error está correlacionado con Xi.
Omisión de variable relevante
¿Por qué se incumple el supuesto 3?
- Debido a que ui y Xi están correlacionados, la media condicional de ui dado Xi es distinta de cero. Esta correlación por lo tanto, viola el tercer supuesto de mínimos cuadrados, y la consecuencia es grave: el estimador MCO es sesgado. Este sesgo no desaparece incluso en muestras muy grandes, y el estimador MCO es inconsistente.